ETL - Extract, Transform and Load
In terms of the fundamentals of the PIMALION platform, ETL (Extract Transform, Load) is one of the three main modules linked to the other two: PIM and DAM, and to all publications for which information imports or exports are useful or necessary.
An ETL module will be at the heart of the PDM module's operation, and also in the management of publications in the DPS module, for supplying them with data and managing changes and updates to digital and print publications.
Goals
The ETL of the pimalion solution has the objectives of:
- Extract data:
The main objective of ETL is to extract data from heterogeneous sources such as databases, flat files or applications.This step is crucial because it makes it possible to collect all the data necessary to feed the decision-making system. - Transform data :
Once the data has been extracted, it must be transformed to be adapted to the data system data model.This step includes several sub-steps such as data cleaning, standardization, consolidation and data enrichment.The objective is to have consistent and homogeneous data for effective analysis. - Load data:
Finally, the transformed data is loaded in the decision-making system. This step includes several sub-steps such as checking data integrity, error management and updating existing data.
The aim is to have reliable, up-to-date data so that interested parties can quickly and effectively obtain the correct product information.
In summary, the ETL of the Pimalion solution aims to extract, transform and charge data into the decision -making system in order to obtain a consolidated and coherent view of the information.
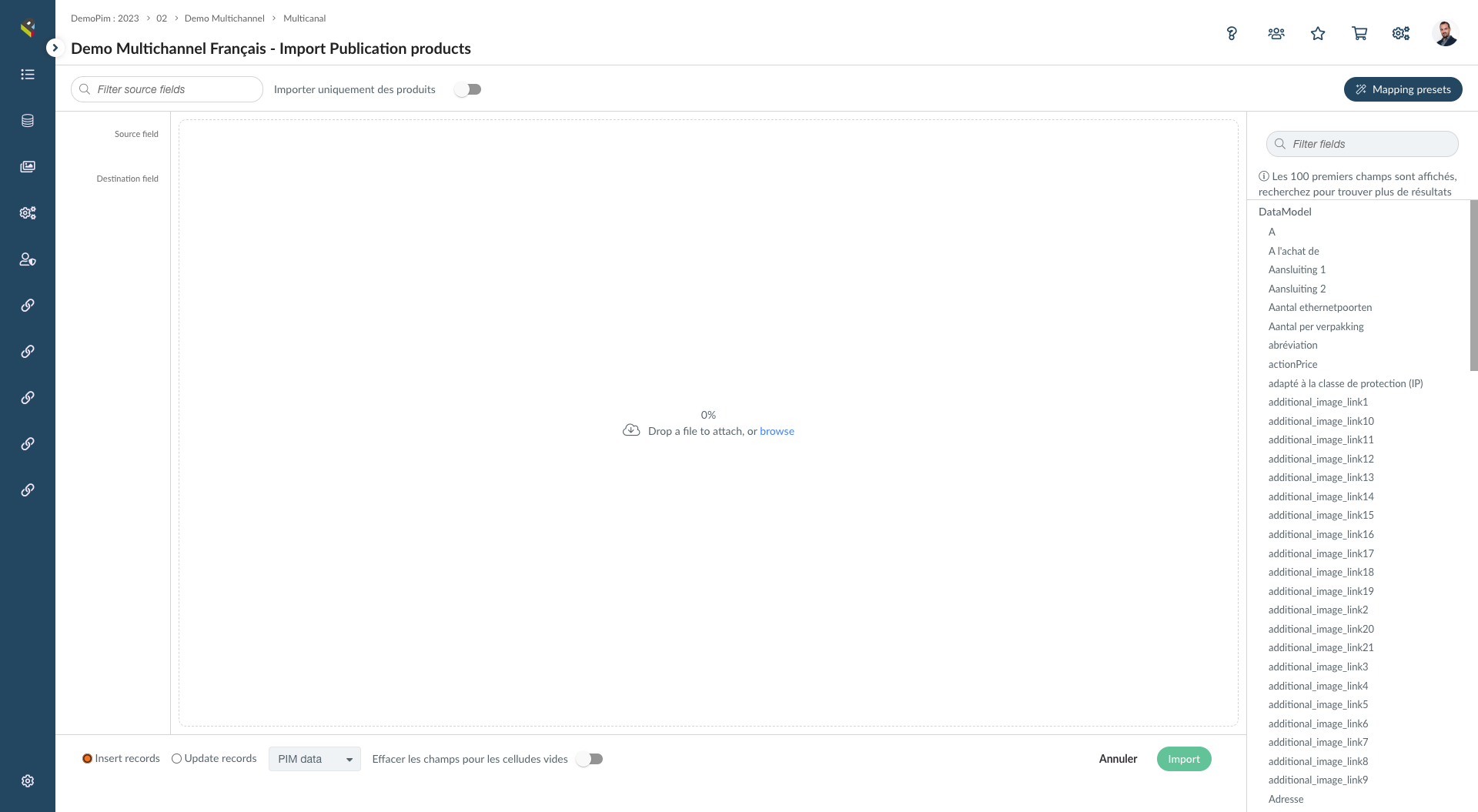
Pimalion ETL module
Pimalion brings an ETL solution (Extract, Transform and LOAD) which makes it possible to collect, transform and load data from different sources.
This solution offers several advantages for companies that wish to improve their data management process.
First of all, Pimalion allows easy integration of data from different sources such as databases, flat files, cloud applications, etc. This integration is done automatically and quickly thanks to the self-discovery functionality of data sources.
Then, Pimalion offers great flexibility in data processing.
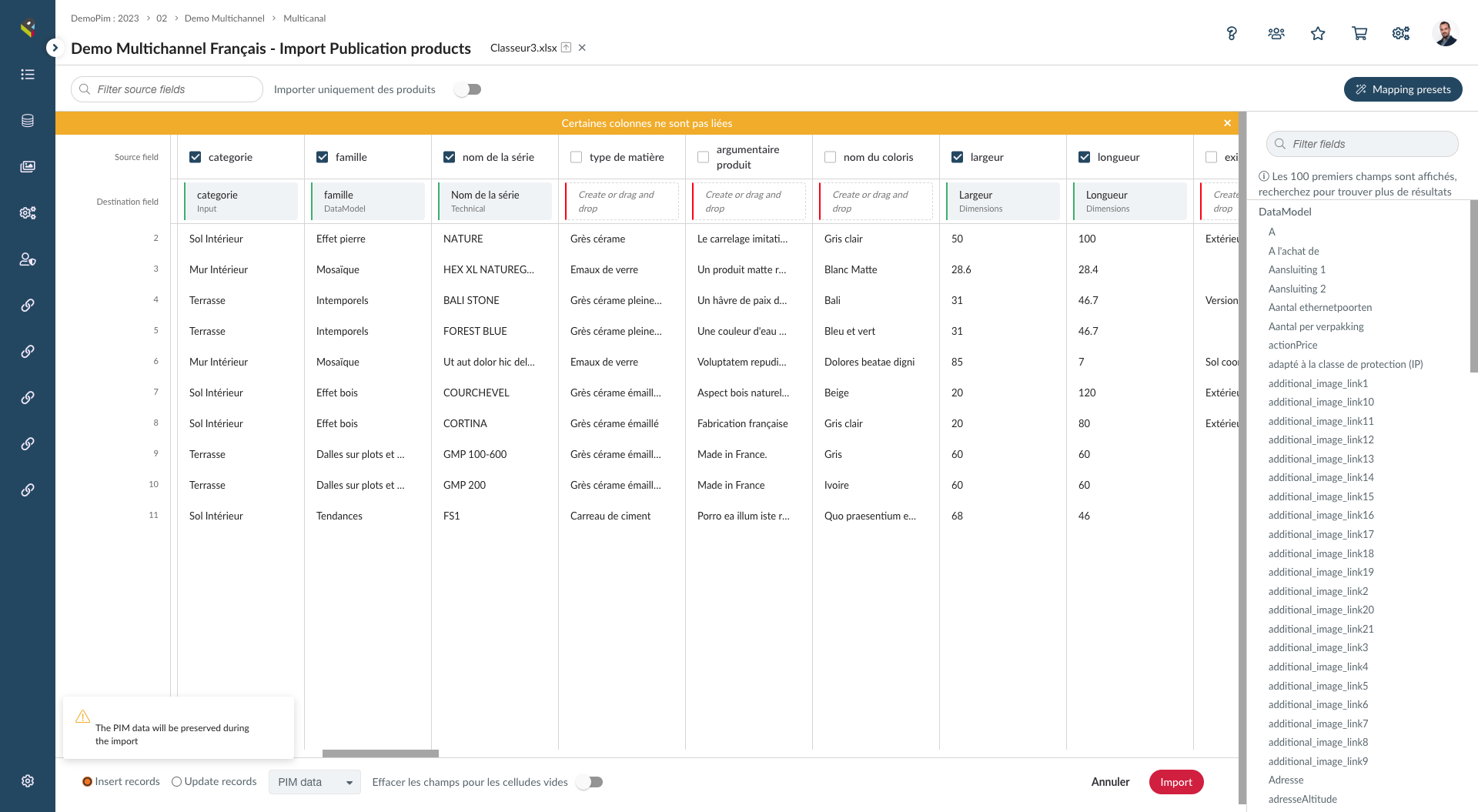
Users can easily define transformation rules to clean, normalize and enrich data. In addition, Pimalion automates these rules to ensure that the data is always consistent and up to date.
finally, Pimalion offers great performance when loading data in the target system. This solution uses advanced optimization techniques to speed up the loading process. In addition, Pimalion is able to manage large volumes of data without affecting the performance of the target system.
In summary, here are the key advantages of using the ETL Pimalion solution:
- Easier integration of data from different sources and saved mapping models
- Flexibility in information transformation and data manipulation
- Great performance when loading data in the target system